Kubernetes Components
When you deploy Kubernetes, you get a cluster.
A Kubernetes cluster consists of a set of worker machines, called nodesA node is a worker machine in Kubernetes. , that run containerized applications. Every cluster has at least one worker node.
The worker node(s) host the PodsThe smallest and simplest Kubernetes object. A Pod represents a set of running containers on your cluster. that are the components of the application workload. The control planeThe container orchestration layer that exposes the API and interfaces to define, deploy, and manage the lifecycle of containers. manages the worker nodes and the Pods in the cluster. In production environments, the control plane usually runs across multiple computers and a cluster usually runs multiple nodes, providing fault-tolerance and high availability.
This document outlines the various components you need to have a complete and working Kubernetes cluster.
Here’s the diagram of a Kubernetes cluster with all the components tied together.
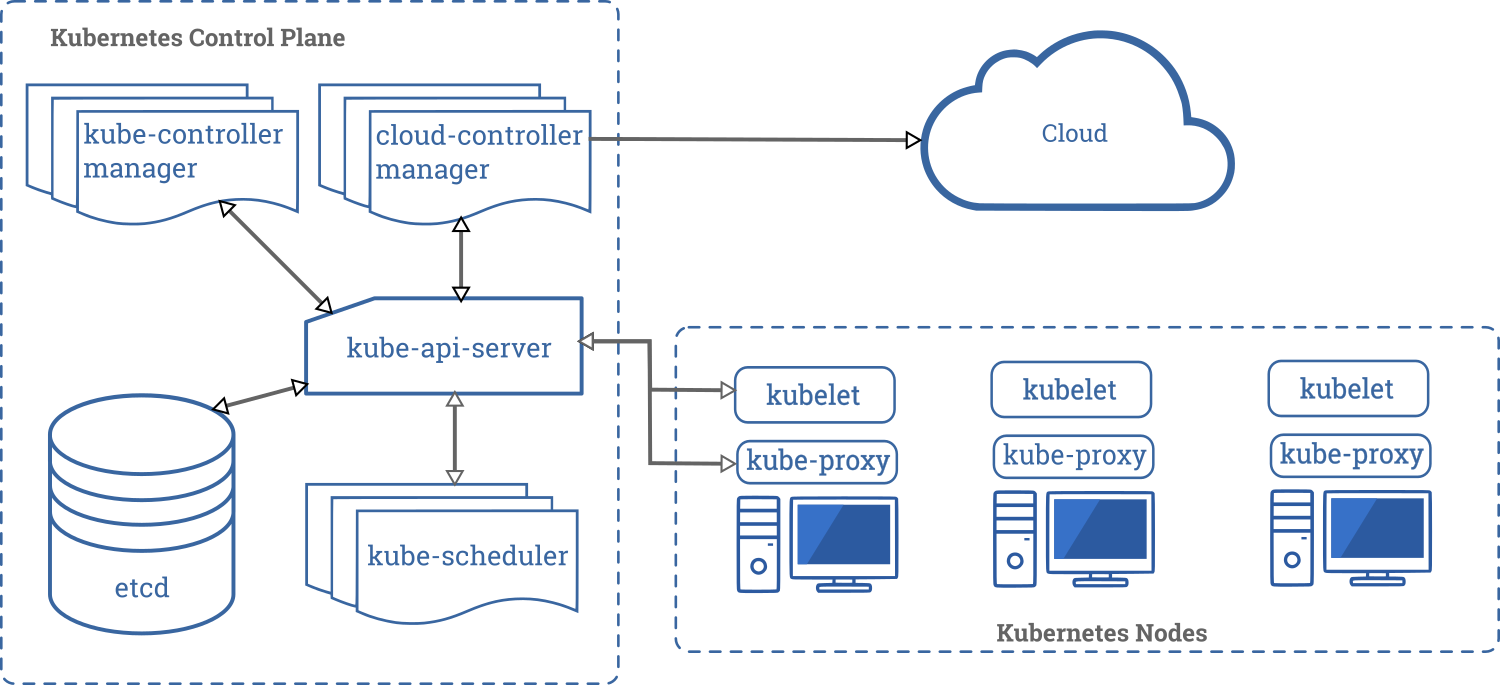
Control Plane Components
The Control Plane’s components make global decisions about the cluster (for example, scheduling), as well as detecting and responding to cluster events (for example, starting up a new podThe smallest and simplest Kubernetes object. A Pod represents a set of running containers on your cluster. when a deployment’s replicas field is unsatisfied).
Control Plane components can be run on any machine in the cluster. However, for simplicity, set up scripts typically start all Control Plane components on the same machine, and do not run user containers on this machine. See Building High-Availability Clusters for an example multi-master-VM setup.
kube-apiserver
The API server is a component of the Kubernetes control planeThe container orchestration layer that exposes the API and interfaces to define, deploy, and manage the lifecycle of containers. that exposes the Kubernetes API. The API server is the front end for the Kubernetes control plane.
The main implementation of a Kubernetes API server is kube-apiserver. kube-apiserver is designed to scale horizontally—that is, it scales by deploying more instances. You can run several instances of kube-apiserver and balance traffic between those instances.
etcd
Consistent and highly-available key value store used as Kubernetes’ backing store for all cluster data.
If your Kubernetes cluster uses etcd as its backing store, make sure you have a back up plan for those data.
You can find in-depth information about etcd in the official documentation.
kube-scheduler
Control plane component that watches for newly created PodsThe smallest and simplest Kubernetes object. A Pod represents a set of running containers on your cluster. with no assigned nodeA node is a worker machine in Kubernetes. , and selects a node for them to run on.
Factors taken into account for scheduling decisions include: individual and collective resource requirements, hardware/software/policy constraints, affinity and anti-affinity specifications, data locality, inter-workload interference, and deadlines.
kube-controller-manager
Control Plane component that runs controllerA control loop that watches the shared state of the cluster through the apiserver and makes changes attempting to move the current state towards the desired state. processes.
Logically, each controllerA control loop that watches the shared state of the cluster through the apiserver and makes changes attempting to move the current state towards the desired state. is a separate process, but to reduce complexity, they are all compiled into a single binary and run in a single process.
These controllers include:
- Node Controller: Responsible for noticing and responding when nodes go down.
- Replication Controller: Responsible for maintaining the correct number of pods for every replication controller object in the system.
- Endpoints Controller: Populates the Endpoints object (that is, joins Services & Pods).
- Service Account & Token Controllers: Create default accounts and API access tokens for new namespaces.
cloud-controller-manager
cloud-controller-manager runs controllers that interact with the underlying cloud providers. The cloud-controller-manager binary is an alpha feature introduced in Kubernetes release 1.6.
cloud-controller-manager runs cloud-provider-specific controller loops only. You must disable these controller loops in the kube-controller-manager. You can disable the controller loops by setting the --cloud-provider flag to external when starting the kube-controller-manager.
cloud-controller-manager allows the cloud vendor’s code and the Kubernetes code to evolve independently of each other. In prior releases, the core Kubernetes code was dependent upon cloud-provider-specific code for functionality. In future releases, code specific to cloud vendors should be maintained by the cloud vendor themselves, and linked to cloud-controller-manager while running Kubernetes.
The following controllers have cloud provider dependencies:
- Node Controller: For checking the cloud provider to determine if a node has been deleted in the cloud after it stops responding
- Route Controller: For setting up routes in the underlying cloud infrastructure
- Service Controller: For creating, updating and deleting cloud provider load balancers
- Volume Controller: For creating, attaching, and mounting volumes, and interacting with the cloud provider to orchestrate volumes
Node Components
Node components run on every node, maintaining running pods and providing the Kubernetes runtime environment.
kubelet
An agent that runs on each nodeA node is a worker machine in Kubernetes. in the cluster. It makes sure that containersA lightweight and portable executable image that contains software and all of its dependencies. are running in a PodThe smallest and simplest Kubernetes object. A Pod represents a set of running containers on your cluster. .
The kubelet takes a set of PodSpecs that are provided through various mechanisms and ensures that the containers described in those PodSpecs are running and healthy. The kubelet doesn’t manage containers which were not created by Kubernetes.
kube-proxy
kube-proxy is a network proxy that runs on each nodeA node is a worker machine in Kubernetes. in your cluster, implementing part of the Kubernetes ServiceA way to expose an application running on a set of Pods as a network service. concept.
kube-proxy maintains network rules on nodes. These network rules allow network communication to your Pods from network sessions inside or outside of your cluster.
kube-proxy uses the operating system packet filtering layer if there is one and it’s available. Otherwise, kube-proxy forwards the traffic itself.
Container Runtime
The container runtime is the software that is responsible for running containers.
Kubernetes supports several container runtimes: DockerDocker is a software technology providing operating-system-level virtualization also known as containers. , containerdA container runtime with an emphasis on simplicity, robustness and portability , CRI-OA lightweight container runtime specifically for Kubernetes , and any implementation of the Kubernetes CRI (Container Runtime Interface).
Addons
Addons use Kubernetes resources (DaemonSetEnsures a copy of a Pod is running across a set of nodes in a cluster.
,
DeploymentAn API object that manages a replicated application.
, etc)
to implement cluster features. Because these are providing cluster-level features, namespaced resources
for addons belong within the kube-system namespace.
Selected addons are described below; for an extended list of available addons, please see Addons.
DNS
While the other addons are not strictly required, all Kubernetes clusters should have cluster DNS, as many examples rely on it.
Cluster DNS is a DNS server, in addition to the other DNS server(s) in your environment, which serves DNS records for Kubernetes services.
Containers started by Kubernetes automatically include this DNS server in their DNS searches.
Web UI (Dashboard)
Dashboard is a general purpose, web-based UI for Kubernetes clusters. It allows users to manage and troubleshoot applications running in the cluster, as well as the cluster itself.
Container Resource Monitoring
Container Resource Monitoring records generic time-series metrics about containers in a central database, and provides a UI for browsing that data.
Cluster-level Logging
A cluster-level logging mechanism is responsible for saving container logs to a central log store with search/browsing interface.
What's next
- Learn about Nodes
- Learn about Controllers
- Learn about kube-scheduler
- Read etcd’s official documentation
Feedback
Was this page helpful?
Thanks for the feedback. If you have a specific, answerable question about how to use Kubernetes, ask it on Stack Overflow. Open an issue in the GitHub repo if you want to report a problem or suggest an improvement.